

Menu
Modeling Risk
Friday, August 14, 2020
By Cristian deRitis

The early returns on the impact of the pandemic on credit performance are now in, with some surprising results. The unprecedented spike in unemployment caused by COVID-19 naturally yielded predictions for a significant increase in defaults, but these prognostications have proved false - at least thus far.
What factors stemmed the tide of defaults, and what has the pandemic taught us about properly training models during periods of severe economic displacement?
Every day, month or year brings an additional data point to help us assess the accuracy of our existing models and predictions. Some data points generate the exhilaration of being spot on with our forecasts (even if we know in our statistical hearts that we were lucky). When the data point surfaces an error in our forecast, it offers an opportunity to understand what went wrong and the chance to improve or change our modeling techniques to do better next time.

Of course, this brings us to the coronavirus and the havoc it is wreaking - not only on our health and our economy but even our forecasting models. My email inbox has been filled in recent weeks with requests from credit loss modelers, accountants and senior management teams who are all trying to figure out how to deal with double-digit unemployment and losses in GDP that haven't been observed since the Great Depression.
Early in the crisis, questions revolved around the level of confidence that we had in our forecasts, which called for unemployment to rise to stratospheric levels. Were we really confident that unemployment could rise so high, so quickly?
The question now is how can high unemployment be properly incorporated within models to generate reasonable and supportable forecasts? Historically, the correlation between charge-offs and the unemployment rate has been high. Consequently, many credit loss models - particularly those involving consumer loans such as mortgages or credit cards - have been trained on unemployment rates.
Figure 1: The Connection Between Unemployment and Credit Card Default
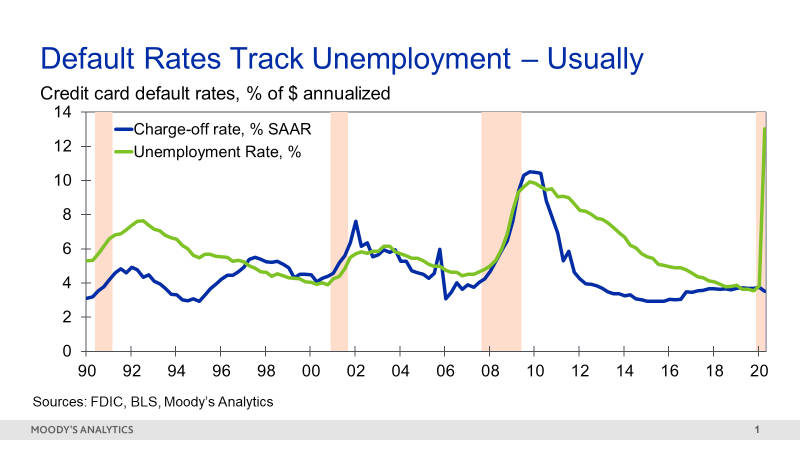
For some products, the correlation between new unemployment insurance claims and delinquency rates has been even higher.
Figure 2: The Link Between Unemployment Claims and Delinquency Rates
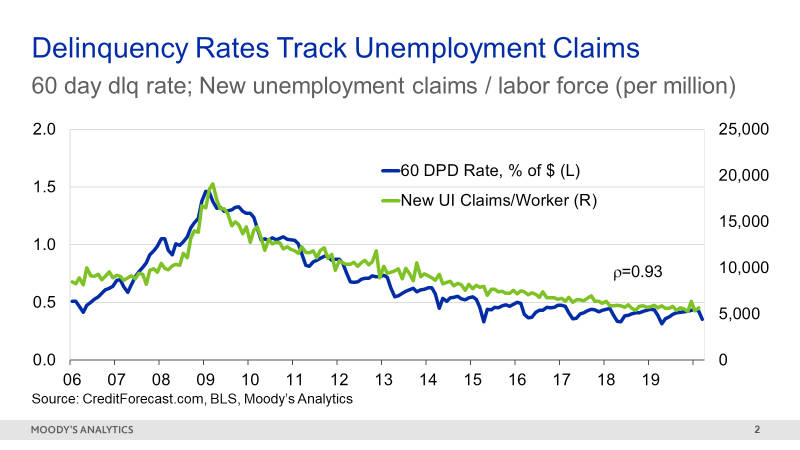
Portfolio managers could practically set their watches by this relationship. If unemployment rose, it was a safe bet that loan defaults would rise by a similar magnitude a few months later.
The Great Recession of 2009 upended this relationship for several years, given its severity and the fact that it was concentrated in the household sector. Outside of this episode, the correlation has held up well. Indeed, it was re-established in the past few years, once the full effects of the Great Recession were finally over and household finances were on a stronger footing.
A New, Dysfunctional Era Disrupts Default Predictions
The onset of COVID-19 changed things overnight. Governments imposed shutdowns on business activity, and the demand for leisure, hospitality and retail services waned significantly.
Unemployment rose as a direct consequence. While entirely justifiable, these atypical acts disrupted the finely-tuned relationship between the unemployment rate and charge-offs.
Models trained on history knew no better than to send default rates soaring when unemployment spiked in March and April. But the overall default impact was offset by the unprecedented amount of government support provided to households in the form of stimulus checks and unemployment insurance benefits.
So, while the unemployment rate soared, household incomes were supported, and actually rose in many cases. Flush with cash and propped up by generous forbearance programs, households continued to pay their bills, sending delinquencies and charge-offs down - exactly opposite from what we expected.
Figure 3: Stimulus Plans Provide Temporary Income Relief
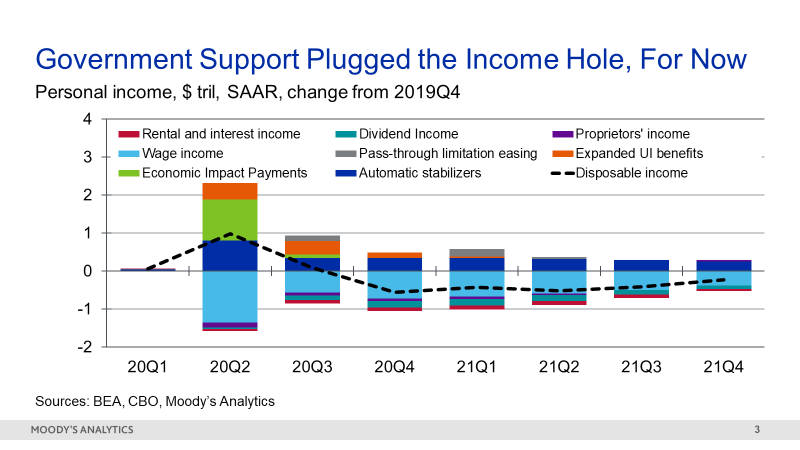
This situation boils down to a classic missing variables problem: an omitted variable issue, in econometric terms. Essentially, if we leave out an important explanatory variable from our forecasting model, then the estimated coefficients may be biased and the forecasts produced may be unstable or inaccurate.
While the unemployment rate may have been a great proxy variable historically, it wasn't the true driver of default risk. Borrowers don't necessarily stop paying their bills just because they are suddenly unemployed: just think of a lottery winner or someone who earns income from dividends or rents in addition to drawing a salary.
Rather, borrowers stop paying because their incomes are disrupted. But in the current environment, household incomes weren't disrupted - at least not in the short term. As a result, payments continued to flow, despite the adverse unemployment rate signal.
Imperfect Solutions
So, what's the solution? The most obvious solution is to train models on measures of income rather than, or in addition to, the unemployment rate.
While attractive, an issue with this approach is that income data can be imprecise. For example, while wage and salary income may be most easily measured, they also offer an incomplete picture of total income. Conversely, interest, dividend and rental income may be volatile and uneven.
Consistent measurement is also a potential problem, with some sources reporting after-tax income while others report income before taxes. Complicating matters further, income data may come with a lag limiting its usefulness for real-time analysis.
None of these issues is insurmountable, but they do require some careful thought and attention. Unemployment is much more easily defined and is reported monthly by the Bureau of Labor Statistics, making it attractive as a measure given its (typical) correlation with income.
Credit modeling teams across the country are now busy reconstructing and refitting their forecasting models in light of COVID-19. But developing, documenting and validating a new model takes time, if we follow a standard model governance process with all its inherent checks and controls.
Of course, CECL, stress testing, pricing and origination decisions wait for no person and no model. What's an institution to do in the interim, while models are being reconfigured to deal with new data and behavior? They can't simply shut down and wait.
Parting Thoughts: Adapt, Modify and Interpolate
The options for dealing with extreme values are threefold. First, model users can choose to run their models as they are, and then override them with “reasonable” adjustments. But what's reasonable for an event that has never been observed historically? To a large extent, adjustments will be educated guesses based on experience and forecast sensitivity analysis around multiple scenarios.
A second approach being adopted by some is a modification of the economic inputs feeding into their loss models. Users may try to define an “effective unemployment rate” that incorporates the fact that the unemployed today are still receiving unemployment benefit checks.
However, defining a reasonable effective unemployment rate may be even more challenging than determining an override for the loss estimate. A reviewer or auditor may be more apt to challenge manipulation of input values versus a transparent, well-documented, on-the-top adjustment.
A third method relies on interpolation. Perhaps we feel confident in our loss estimates from the first quarter and third quarter, but we don't trust the second-quarter values. Interpolating across these periods may be a reasonable approach, supported by the fact that stimulus checks are minimizing the rise of losses in the short term.
Regardless of the approach, to be fully transparent to downstream stakeholders and to mitigate the risk of an incorrect assumption, it's important to develop a process around a model.
A forecaster's work is never done. The world keeps changing and evolving, leading to a constant need to revise and update our predictions.
Of course, our desire is always to be accurate and to foresee events with enough time to take appropriate actions beforehand, rather than reacting to them once they hit. That's not always possible, but it's the forecast errors that make our jobs challenging and, ultimately, rewarding.
If we knew the outcomes with certainty, then there wouldn't be much for modelers, forecasters or risk managers to contribute.
Cristian deRitis is the Deputy Chief Economist at Moody's Analytics. As the head of model research and development, he specializes in the analysis of current and future economic conditions, consumer credit markets and housing. Before joining Moody's Analytics, he worked for Fannie Mae. In addition to his published research, Cris is named on two U.S. patents for credit modeling techniques. He can be reached at cristian.deritis@moodys.com.
Advertisement

•Bylaws •Code of Conduct •Privacy Notice •Terms of Use © 2024 Global Association of Risk Professionals
 More
More




